Vista Registry – Copy To ContextMenuHandlers

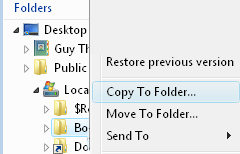
Imagine this scenario: You wish to copy a file from one folder to another. What this registry tweak will do is place ‘Copy To’ on the Windows Explorer shortcut menu. Once you right-click a file and select ‘Copy to Folder’, a dialog box opens inviting you to choose the file destination.
Topics for adding ‘Copy To’
♦
Instructions to Add ‘Copy To’ to the Explorer Context Menu
- Launch Regedit
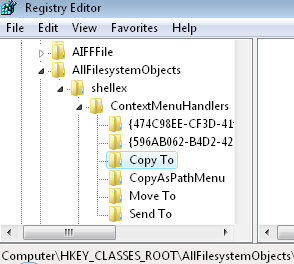
Navigate to this key: - HKEY_CLASSES_ROOT\AllFilesystemObjects\shellex \ContextMenuHandlers\
- Create a new Key. Name the new Key: Copy To

- In the right-hand pane, double click the existing REG_SZ called Default, and set the value to:
{C2FBB630-2971-11d1-A18C-00C04FD75D13} - Note: you do need the {curly brackets} for this CLSID.
- Close regedit, no need to reboot or even logoff, just launch Windows Explorer, right-click a file and enjoy the ‘Copy To Folder’ feature.

Addendum: You can create another registry entry, which Moves instead of Copies. In the CLSID, change C2FBB630 to C2FBB631 and repeat the above. The full name of the Move To value is:
{C2FBB631-2971-11d1-A18C-00C04FD75D13} Thanks to Aleksey Tchekmarev for additional material.
Recommended: Solarwinds’ Permissions Analyzer – Free Active Directory Tool

I like thePermissions Analyzer because it enables me to see WHO has permissions to do WHAT at a glance. When you launch this tool it analyzes a users effective NTFS permissions for a specific file or folder, and takes into account network share access, then displays the results in a nifty desktop dashboard!
Think of all the frustration that this free SolarWinds utility saves when you are troubleshooting authorization problems for user’s access to a resource. Give this permissions monitor a try – it’s free!
Download SolarWinds’ Free Permissions Analyser – Active Directory Tool
Key Learning Points
- Do you find the ContextMenuHandlers value in HKCU** or HKLM?
Answer: Neither it is in HKEY_CLASSES_ROOT - Do you have to add a value, or modify an existing setting?
Answers:
First, Add a whole new Key (Not just a new value) called Copy To
Second, Modify the REG_SZ called Default. - Is {C2FBB630-2971-11d1-A18C-00C04FD75D13} a String Value or a DWORD?
Answer: REG_SZ (String value). - Do you need to Restart, or merely Logoff / Logon?
Answer: Neither, just launch another Windows Explorer, right-click on a folder and test the ‘Copy To’.
** HKLM is an abbreviation of HKEY_LOCAL_MACHINE, and HKCU is shorthand for HKEY_CURRENT_USER. These acronyms are so well-known that you can even use them in .reg files, Vista will understand and obey the registry instruction.
♦
Warning:
While this ‘Copy To’ registry hack looks flash, it can give problems, Kevin M. kindly sent in this snippet of information.
When I select two or more files in Windows Explorer to open in Notepad or any other program, for every selected file – before opening it in the proper application – I first get a dialog asking me where to move the item. Cancelling this dialog brings up the next asking where to copy the file. Cancelling this dialog leads to opening of the file and bringing up the next files "move-dialog"! Pretty irritating!
Best Practice for Editing the Vista Registry
- Before you make any changes to the registry settings, get into the habit of exporting at the branch of the registry that you are working with.
- Backup the system state before you try anything radical in the registry.
- Check out the .sav files in the \system32\config folder.
- Research Volume Shadow Copy, and test how it restores a previous version of your registry files.
- If your computer has a serious problem, which requires pressing F8 at boot-up, remember to try Last Known Good as your first recovery option.
- Seek alternative methods; think laterally. Instead of risking making changes with your registry editor, what else could you do? I urge you to consider configuring a Group Policy rather than tweaking the registry. Occasionally Vista may provide a new GUI to configure a setting, for example, instead of launching regedit and changing the value for AutoAdminLogon, you could launch the Control Panel –> Users and un-tick the setting called, ‘Users must enter a user name and password.’
- Learn how to perform a remote registry edit with: Connect Network Registry.
- As you work through my registry examples, make a point of studying each page’s ‘Key Learning Points’.
If you like this page then please share it with your friends
Windows Vista Registry Tweaks: